const run = gen => { const g = gen(); const next = data => { let result = g.next(data); //执行生成器中的任务 if (result.done) return result.value; result.value(next); //把next作为回调函数传给thunk函数,实现自动流程控制 }; next(); };
const run = gen => { const g = gen(); const next = data => { let result = g.next(data); if (result.done) return result.value; result.value.then(data => { next(data); }); next(); }; };
functionfoo() { var a = 2; functionbar() { console.log( a ); // 2 } bar(); } foo();
我们关注一下bar()这个函数,根据函数作用域的规则,函数bar()定义于函数foo()之中,那么其内对于变量 a 的引用(这里是RHS引用查询),就会自然而然地去访问其外层作用域即foo()函数的作用域。因为函数 bar() 中没有变量a,而函数作用域是允许嵌套的,并且在进行RHS引用访问时,会进行递归查找。
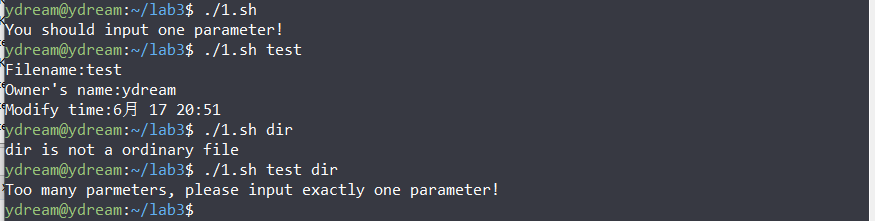
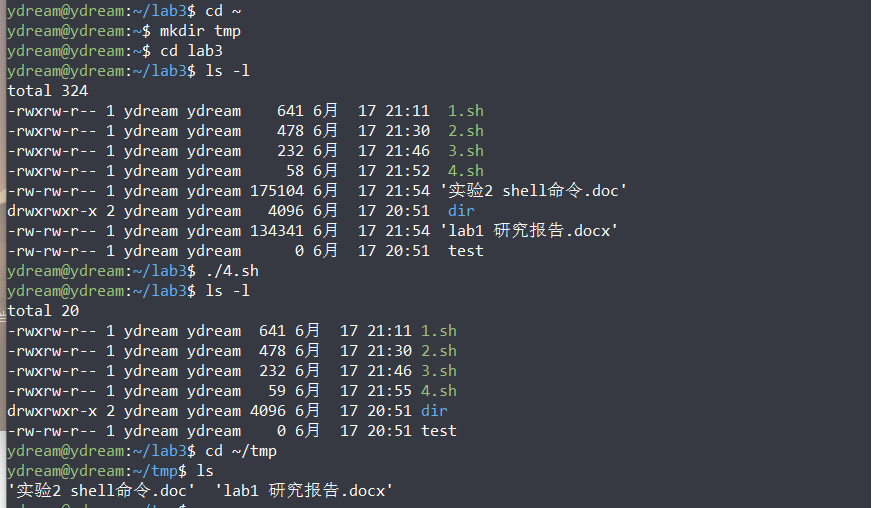
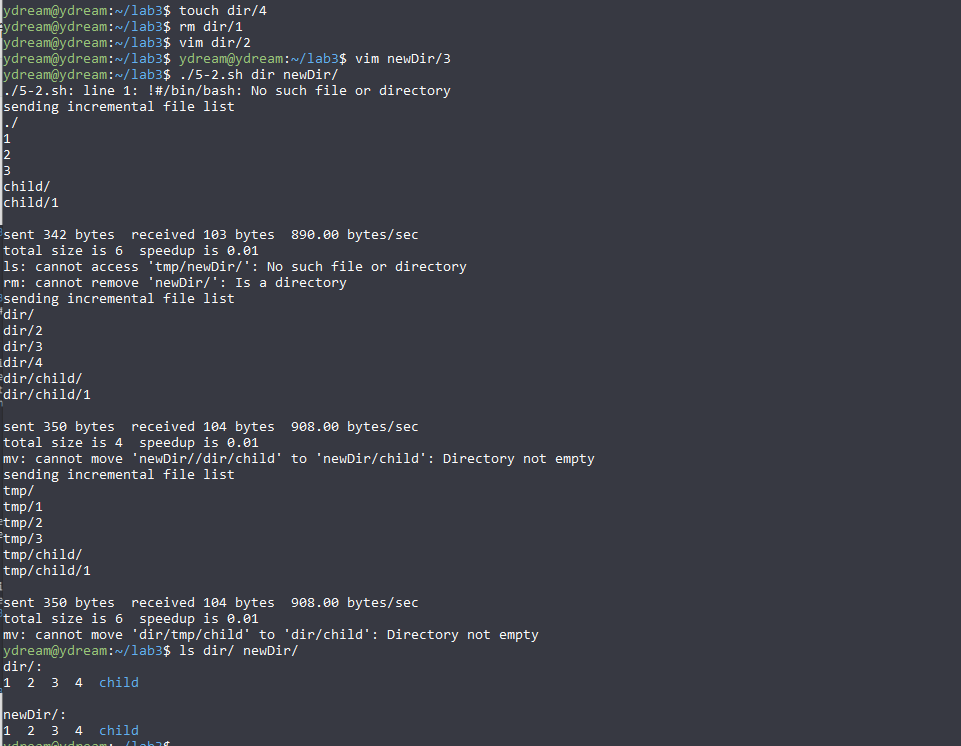
#!/bin/sh echo "normal files:" `find $1 -type f | wc -l` #normal files echo "subdirectory:"`find $1 -type d | wc -l` #subdirectory echo "executable files:" `find $1 -type f -executable | wc -l` #executable files num=0 for file_name in `ls $1` #for each file do file=$1"/"$file_name #get the path if [ -f $file ] #if it is an ordinary file then ch=$(cat $file | wc -c) #get the number of chars num=$(($num+$ch)) fi done echo "total char num: $num"
#!/bin/sh echo -n "Please input the string:" read line ##get input str=`echo $line | tr -c -d [:alpha:] ` ##delete other chars reverse=`echo $str | rev` if [ $str = $reverse ]; ##check if int the same then echo "$str is palindorme." else echo "$str isn't palindorme" fi
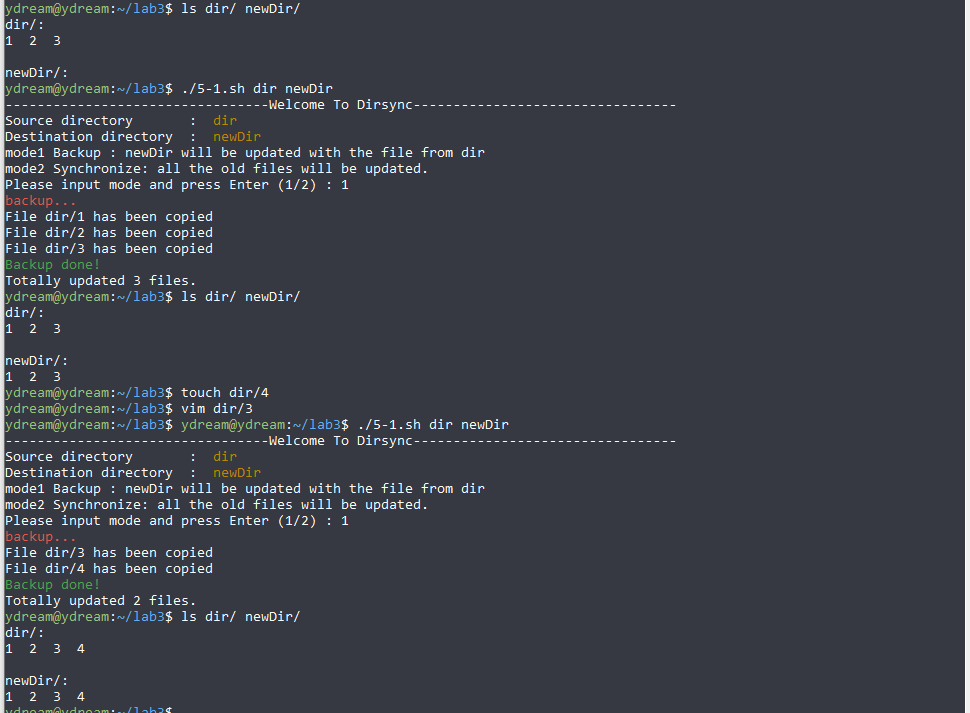
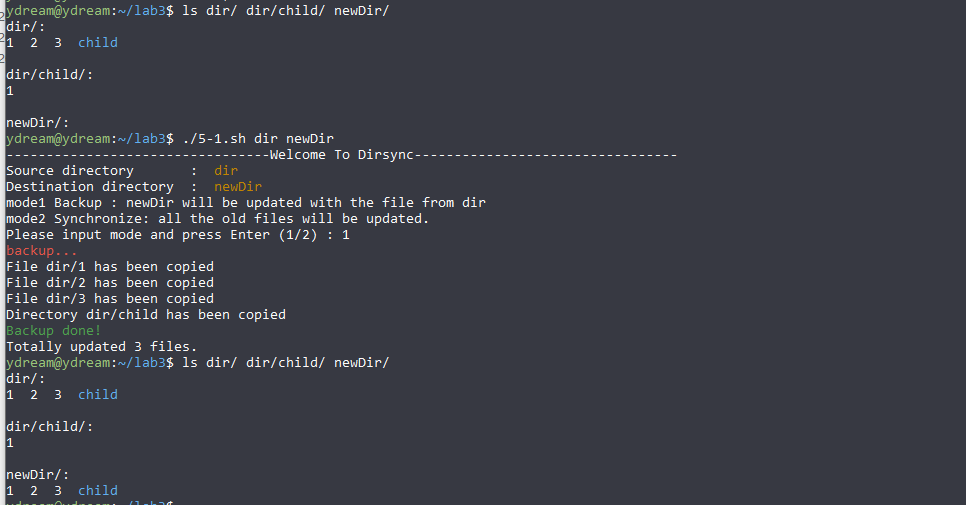
#!/bin/bash # dirsync.sh # Two modes: # 1. back-up # 2. synchronize # Judge the input parameter if [ $# -ne 2 ] #judge the number of parameter then echo "program: $0 needs one prameter." exit 1 fi if [[ ! -d $1 || ! -d $2 ]] #check if they are dictionary then echo "parameters must be dirctory" exit 1 fi # The definitions of functions used # To update file. # @parameters : source file, destination path and source path
function update_file { new_file=$2\/$1 source_file=$3\/$1 if [`! -f $new_file`] && [ `stat -c %Y $new_file` -gt `stat -c %Y $source_file` ] then cp -fp $source_file $new_file echo "File "$source_file" has been copied" cnt_update=$cnt_update+1 # cnt the number return 1 fi return 0 } # To delete the file that doesn't exist in the given source file. # @Parameters : source file, destination path and source path # Use a dictionary /tmp to replace rm function delete_file { if test -f $2\/$1 then : else mv $3\/$1 \/tmp echo "File "$3\/$1" has been deleted" cnt_delete=$cnt_delete+1 # cnt the number return 1 fi return 0 } # To update a directory. # @Parameters : source dir, destination path and source path
function update_dir { cnt=0 if test -d $2\/$1 then for item in $(ls $3\/$1) do if test -d $3\/$1\/$item then update_dir $item $2\/$item $3\/$1 # recursively update elif test -f $3\/$1\/$item then update_file $item $2\/$1 $3\/$1 # check the file if (( $? == 1 )) then cnt=$cnt+1 fi fi done else cp -fpr $3\/$1 $2\/$1 echo "Directory "$3\/$1" has been copied" fi } # To delete the directory that doesn't exist in the given source file. # @Parameters : source dir($1), destination path($2) and source path($3) # Use a dictionary /tmp to replace rm function delete_dir { cnt=0 if test -d $2\/$1 then for item in $(ls $3\/$1) do if test -d $3\/$1\/$item # check if it is a dir then delete_dir $item $2\/$item $3\/$1 # recursively delete continue fi if test -f $3\/$1\/$item # check if it is a file then delete_file $item $2\/$1 $3\/$1 # delete a file if (( $? == 1 )) then cnt=$cnt+1 fi continue fi done else mv $3\/$1 \/tmp # safely remove echo "Directory "$3\/$1" has been deleted" fi } # Main
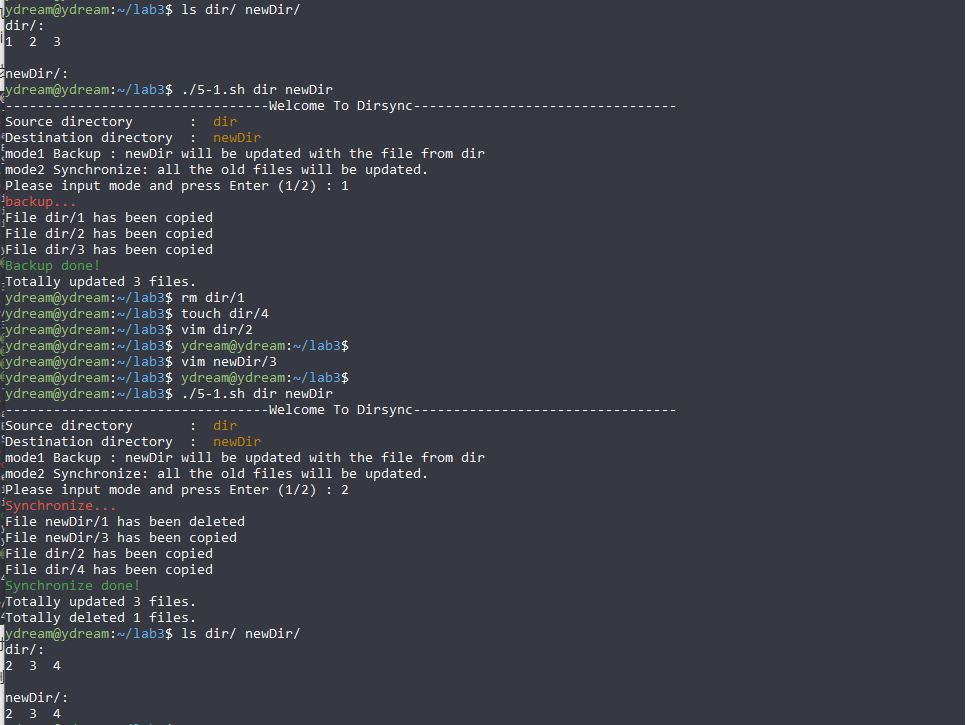
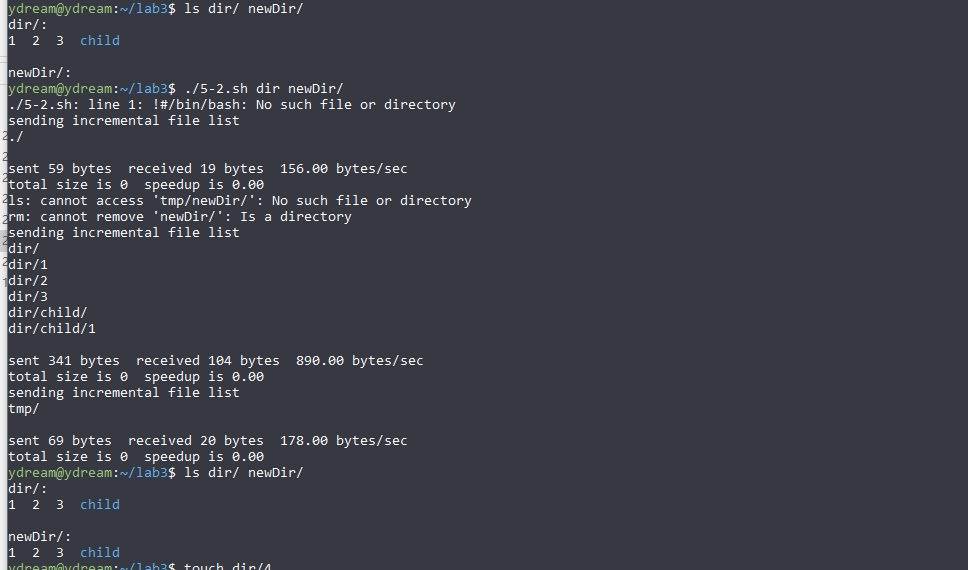
source_dir=${1:-./} destination_dir=${2:-./} declare -i cnt_update=0 # counter of update declare -i cnt_delete=0 # counter of deletion echo "---------------------------------Welcome To Dirsync---------------------------------" echo -e "Source directory : \033[33m ${source_dir} \033[0m" echo -e "Destination directory : \033[33m ${destination_dir} \033[0m" echo "mode1 Backup : ${destination_dir} will be updated with the file from ${source_dir}" echo "mode2 Synchronize: all the old files will be updated." read -p "Please input mode and press Enter (1/2) : " mode
if [ $mode = 1 ] then # back-up echo -e "\033[31mbackup... \033[0m" # Note that the '/' is removed source_dir=${source_dir%/} destination_dir=${destination_dir%/} for item in $(ls ${source_dir}\/) do tmp_path=$source_dir\/$item if test -d $tmp_path then update_dir $item $destination_dir $source_dir elif test -f $tmp_path then update_file $item $destination_dir $source_dir fi done
echo -e "\033[31mSynchronize... \033[0m" source_dir=${source_dir%/} destination_dir=${destination_dir%/} tmp=$source_dir source_dir=$destination_dir destination_dir=$tmp for item in $(ls ${source_dir}\/) do tmp_path=$source_dir\/$item if test -d $tmp_path then delete_dir $item $destination_dir $source_dir elif test -f $tmp_path then delete_file $item $destination_dir $source_dir fi done for item in $(ls ${source_dir}\/) do tmp_path=$source_dir\/$item if test -d $tmp_path then update_dir $item $destination_dir $source_dir elif test -f $tmp_path then update_file $item $destination_dir $source_dir fi done tmp=$source_dir source_dir=$destination_dir destination_dir=$tmp
for item in $(ls ${source_dir}\/) do tmp_path=$source_dir\/$item if test -d $tmp_path then update_dir $item $destination_dir $source_dir elif test -f $tmp_path then update_file $item $destination_dir $source_dir fi done # echo some relavant information echo -e "\033[32mSynchronize done!\033[0m" echo "Totally updated ${cnt_update} files." echo "Totally deleted ${cnt_delete} files." else echo "Invalid input!" fi